Brief
本次仍然是复现Android经典提权漏洞DirtyCow(CVE-2016-5195)
DirtyCow 是一个非常经典的Linux内核提权漏洞,TIMWR团队也依据原本的漏洞原理开发了Android 版本稳定的漏洞利用。相较于PingPong Root(CVE-2015-3636) 而言,个人感觉DirtyCow更像是一个内核逻辑漏洞,对内核一些基本功底以及代码熟悉程度的要求较高。
DirtyCow漏洞主要功能是向一个只读文件中写入任意内容,通过向Android系统中的/system/bin/run-as 文件写入恶意代码,达到提权的目的。
漏洞本身利用流程方面,首先将覆盖目标的文件以只读方式载入内存,并通过/proc/$pid/mem尝试对载入的目标内存中覆盖数据;同时开启另一个线程,不断通过madvise(MADV_DONTNEED) 系统调用释放Cowed的页面,致使获取到了真实的目标文件内存页,并完成了写入(write)操作;
POC 与一些内核基础
以TIMWR提供的exploit为参考,核心代码创建了三个线程:
1 | static void exploit(struct mem_arg *mem_arg) { |
CheckThread
1 | static void *checkThread(void *arg) { |
该线程用于检查DirtyCow的写入操作是否成功,如果已经完成对目标文件的覆盖,则将mem_arg->stop 设置为True,以此来终止另外的两个线程madviseThread以及procselfmemThread.
madviseThread
1 | static void *madviseThread(void *arg) |
在这个线程中,使用了一个特殊的syscall madvise , 这是一个十分危险的系统调用,它允许用户”建议”内核对某段内存做出对应的处理;manual中有如下的描述:
The madvise() system call is used to give advice or directions to the kernel about the address range beginning at address addr and with size length bytes. Initially, the system call supported a set of “conventional” advice values, which are also available on several other implementations. (Note, though, that madvise() is not specified in POSIX.) Subsequently, a number of Linux-specific advice values have been added.
MADV_DONTNEED: Do not expect access in the near future. (For the time being, the application is finished with the given range, so the kernel can free resources associated with it
在漏洞利用过程中使用的MADV_DONTNEED 标识会通知内核本应用在一段时间内都不会再使用某段内存。内核会因此释放掉这段内存来减轻内存资源的占用;当应用再次尝试访问被遗弃的内存时,会触发页错误并重新加载对应的内存。
procselfmemThread
1 | static void *procselfmemThread(void *arg) |
该线程为写入线程,但是并不是直接向目标文件尝试写操作,而是首先将目标文件以只读的方式打开并加载进入当前进程的内存中,并不断的尝试向/proc/self/mem 对应的内存映射区域写入内容。
/proc/{pid}/mem 包含了pid对应进程的内存映射内容,以提供ptrace 系统调用使用,允许其他进程能够访问到pid进程的任意内存;由于该文件是一个pseudo file, 因此也被定义了专门的file_operations处理相应的文件操作:
1 | // from /fs/proc/base.c: |
如果procselfmemThread的写入尝试成功的话,目标文件就会成功被覆盖;
漏洞原理分析与梳理
对于一个只读文件,如果尝试进行写操作的话,正常都应该会抛出类似Permission Denied 的异常,由于对于/proc/{pid}/mem 写入操作的不正常处理,引发了漏洞,下面就将从代码梳理write函数调用后,内核对应的处理过程;
由mem_write 作为入口,将经过一系列的调用,最终到__get_user_pages() 函数来获取覆盖目标文件的内存页;在阅读这段代码的时候,还有一个很有意思的是,实际上读写等操作(mem_read , mem_write),实际上的后续代码路径大体相同,只是使用的FOLL_FLAG回略有差异;
1 | // mm/gup.c __get_user_pages() |
通过faultin_page方法来尝试获取内存页面:
1 | static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma, |
而faultin_page的后续调用如下:
1 | faultin_page |
简单的说,由于目前是尝试向一个只读内存写入内容,faultin_page()方法创建了一个COW PAGE中,而实际不会影响到实际的文件内容;但是,在faultin_page 的最后,罪恶的将FOLL_WRITE标记移除了,这就导致当上层函数__get_user_pages 进行retry再次进入
faultin_page的时候,将不会再有写操作的意图follow_page_mask很有可能返回一个真实的内存页面回来;
可是,由于在处理faultin_page的时候,已经完成了写入操作,因此,retry 中的follow_page_mask调用应当是返回的COW page ,因而不会存在漏洞哇。那么这里就体现出了madviseThread的功能,不断的通过madvise 调用将Dirty Cow Page释放掉,最终达到如下的运行效果(偷图):
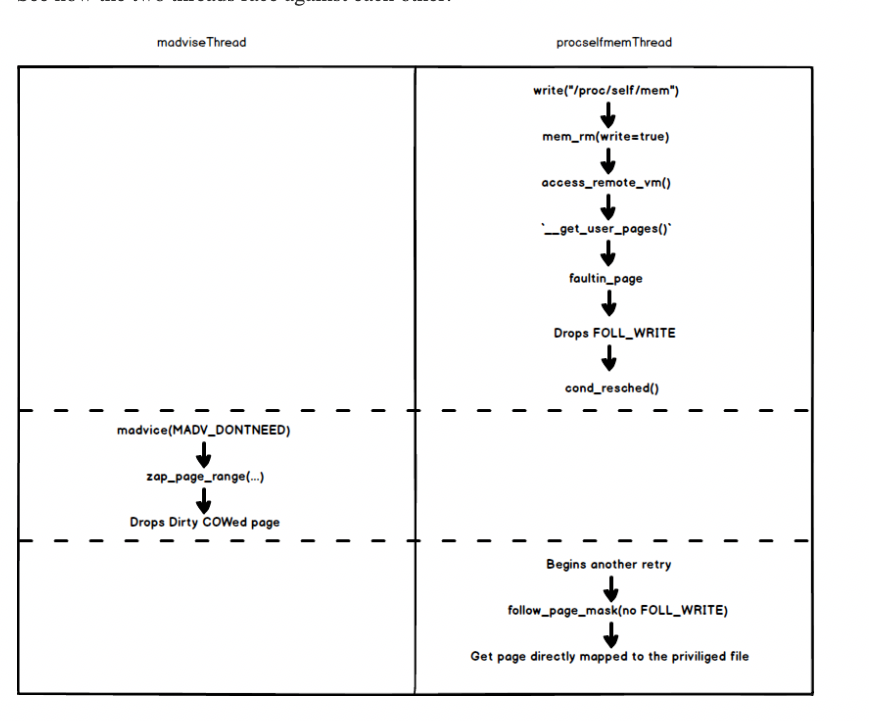
即完成了对真实内存页面的写入操作;
What’s More
Ptrace 的使用
在一些高版本的内核上,对/proc/{pid}/mem 文件时不允许被写入的;当然由于我复现该漏洞使用的是Pingpong Root的模拟器,内核版本非常低,并没有实际遇到上述情况。
但是,如果出现了不能直接写入的情况仍然是有办法触发该漏洞的,方法就是使用ptrace来尝试写入,只需要设置TRACE_PEEKUSR 即可向完成写操作,由于/proc/{pid}/mem本身就是提供给ptrace等调试功能使用的,内核仍会调用mem_write 尝试向/proc/{pid}/mem写入因而触发漏洞;
这部分功能,在exploit中也有相应的代码,即ptraceThread
1 | static int ptrace_memcpy(pid_t pid, void *dest, const void *src, size_t n) |
关于条件竞争利用的效率问题
Unfortunately, you might have guessed it. The answer is the window is actually pretty big, Dirty COW can be triggered pretty reliably even on a single core machine, owing no less to the fact that
__get_user_pagesis explicitly asking the task scheduler to switch to another thread if necessary by callingcond_reschedfor each retry!
对比下正常的文件写入为何不会触发DirtyCow
我们直接尝试写入一个只读文件,而非proc/{pid}/mem 会不会也会出现DirtyCow漏洞呢?
当然不会,我们会直接得到一个最令人头大的segmentation fault
但由于proc/{pid}/mem 是提供给ptrace用于调试的,可能因此才会进行一次Dirty mark Cow Page的操作;
而当我们尝试直接向只读文件写入,会交给内核的MMU模块处理,调用到如下的函数进行处理:
1 | static noinline void |
相对于faultin_page的处理流程,bad_area_access_error会果断的抛出SIGSEGV信号而不进行handle_mm_fault处理,因此,也就不会有Dirty marked Cow PAGE出现