Brief
本次尝试复现学习的是DirtyPipe(CVE-2022-0847),这是去年火爆一时的漏洞. 最近在和dalao们交流过程中发现该漏洞涉及到的一些内核处理过程,在其他漏洞的利用中也会有一些启发。值得仔细学习一下。
DirtyPipe的发现者专门搭建了一个网站来介绍漏洞发现的巧妙经历,线上BUG以及漏洞的分析排查,以及用于验证漏洞的poc. 时隔一年多,网上也已经有不同dalao们的解析文章从不同的角度分析和理解DirtyPipe。因此复现起来并不算困难,但是仍有一些小细节容易被忽略.
从漏洞的危害程度上,发现者将该漏洞类比DirtyCow,也就是可以写一些只读文件。以本地提权为目标的话,依旧是patch一些带有suid的可执行文件或者是在系统中直接添加一个用户。但是相比于DirtyCow,DirtyPipe能够写的内容/范围会有一定的限制但是不需要任何竞争因素触发会更稳定一些。
(本次漏洞复现学习使用的环境来自chenaotian 搭建的docker,我也将环境&exp在我自己的github上做了备份,参考的内核版本为linux-5.16.10)
漏洞原理学习
pipe 与 pipe_write
pipe在Linux中是一种典型的进程间通信的方式,通过pipe系统调用就可以生成一组管道,从一端写入另一端读取。在内核中使用一个struct pipe_inode_info 维护pipe
1 | // https://elixir.bootlin.com/linux/v5.16.10/source/include/linux/pipe_fs_i.h#L58 |
pipe中的内容传递则依赖其中的struct pipe_buffer来完成,在pipe_buffer中维护了一组内存页面,通过向内存页中写入/读取数据来完成进程间数据内容的交换。代码注释中也有说明pipe_buffer是一组环形数组,依次循环使用。
1 | // https://elixir.bootlin.com/linux/v5.16.10/source/include/linux/pipe_fs_i.h#L17 |
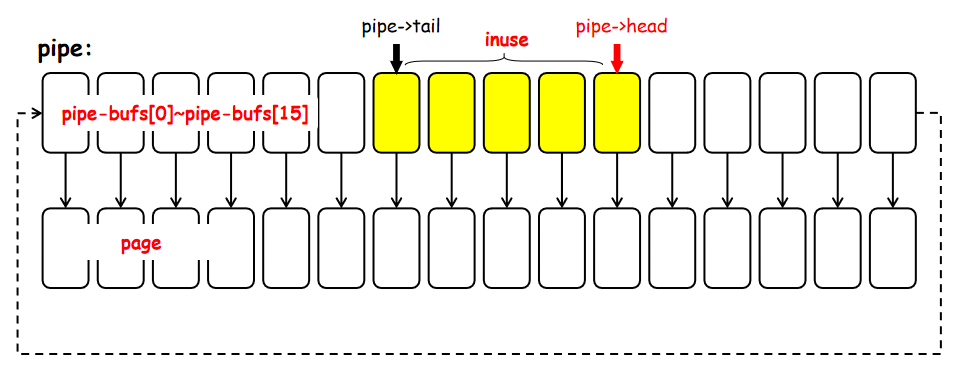
pipe_inode_info中包含了pipe->head和pipe->tail用于记录当前数据读写的位置,在用户空间中,通过write系统调用即可向pipe_buffer中写入数据,切换到内核空间后会由pipe_write函数来处理.
1 | static ssize_t |
从上面的代码可以看出pipe_write的处理包括两个关键场景:
判断当前
pipe->buf是否满足续写条件,满足则继续在当前page中写入内容;当前
pipe->buf不满足续写条件或者没有初始化时,会为pipe->buf申请一个新的page并向其写入内容
当前pipe->buf的续写条件主要包括page中剩余的空间仍能满足数据的写入大小,并且需要pipe->buf->flags包含PIPE_BUF_FLAG_CAN_MERGE; 而恰好pipe->buf在申请page的时候默认就会设置PIPE_BUF_FLAG_CAN_MERGE. 这就为DirtyPipe的出现埋下了伏笔;
splice 系统调用
splice 系统调用是Linux 2.6.17引入的,其功能是在两个文件描述符(file descriptors)之间拷贝数据,省略了内核空间与用户空间之间的拷贝过程,因此具有更好的性能优势;
上文中的pipe正式一组文件描述符,也就是splice系统调用重点处理的场景之一。当将一个文件写入pipe过程即如下图所示:
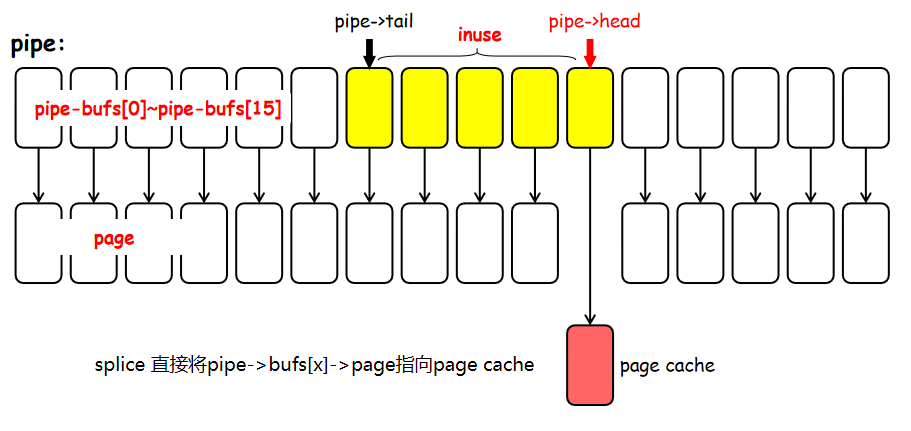
通过将当前的pipe->buf中的page直接替换为从文件描述符中读取到的page cache 做到高效的数据传递。
splice的处理过程比较长,可以简化为以下的调用流程:
SYSCALL_DEFINE6(splice,...)->__do_sys_splice->__do_splice->do_splice
splice_file_to_pipe->do_splice_to
generic_file_splice_read
call_read_iter->filemap_read
copy_page_to_iter->copy_page_to_iter_pipe
copy_page_to_iter_pipe函数即为处理page替换的函数,也就是出现漏洞的位置:
1 | // lib/iov_iter.c |
Okay, 清晰明了的page替换过程,但是好像忘记了什么…
没错,就是pipe->buf->flags中的PIPE_BUF_FLAG_CAN_MERGE 没有被清除。回顾下上文,这个flag是用于标记是否可以在当前pipe->buf->page上继续写入内容的。并且这个flag默认就会被设置成PIPE_BUF_FLAG_CAN_MERGE.
因此,当下次pipe_write写入的长度只要不超过当前pipe_buffer的剩余空间,写入的内容就会覆盖掉由splice系统调用传递进来的文件描述符所对应的page cache. 传递的文件可能是一个只读文件,但是其page cache中的内容却被篡改了。
漏洞原理总结
splice系统调用通过将文件的page cache直接替换pipe->buf->page, 高效的完成了数据拷贝工作。但是由于没有将PIPE_BUF_FLAG_CAN_MERGE清空,导致page替换后,pipe可以向原本只读的文件page cache中写入内容。且内容可以被用户空间通过write系统调用向pipe中写入任意数据。以次完成只读文件的篡改。
但是,这种篡改只能修改page cache中的内容,并不会对硬盘中的文件产生修改,当page cache被释放的时候,对应产生的修改也会被修复。这当然有利有弊,在后续的文章中会专门讨论下。
漏洞利用 Exploit
漏洞的发现者公开过他的poc,注释完整,代码逻辑清晰。后续基于DirtyPipe完成的一些其他利用基本也是照抄了部分的代码。下面就以这个poc代码为基础看下如何触发DirtyPipe。
首先第一步是创建一个pipe,并且将pipe中的所有pipe_buf都先设置好PIPE_BUF_FLAG_CAN_MERGE flag
1 | /** |
持续向pipe内写入内容直至填满所有的pipe_buffer,每个buffer就全部都会被设置成PIPE_BUF_FLAG_CAN_MERGE flag, 接着再将pipe中的所有内容全部都读取出来,就得到了一个“空”的pipe,其所有的page都是可以被续写的。
第二步,以只读(O_RDONLY)方式打开一个文件,并通过splice将文件读取1字节到准备好的pipe
1 | int main(int argc, char **argv) { |
splice完成后只读文件的page cache就会替换到pipe内的一个pipe_buffer。
最后,通过write向pipe中继续写入即可改写page cache中的内容了
1 | int main(int argc, char **argv) { |
利用限制
在poc中描述了DirtyPipe利用时需要注意的一些限制:
There are two major limitations of this exploit: the offset cannot
be on a page boundary (it needs to write one byte before the offset
to add a reference to this page to the pipe), and the write cannot
cross a page boundary.
单次触发DirtyPipe(触发一次splice)只能控制一个内存页(4K)大小的内容;
DirtyPipe无法改变目标文件的大小;
每个内存页的边界位置是无法被覆盖的,由于需要触发一次splice将内存页替换到pipe_buffer中;
1 | loff_t offset = strtoul(argv[2], NULL, 0); |
总结
DirtyPipe(CVE-2022-0847)是一个很有趣的漏洞,无论是漏洞发现的过程还是其本身的原理都能学习到不少的知识。配合漏洞环境,我也首次尝试用gdb调试了下内核,虽然还是很蹩脚但聊胜于无吧。
作为一个Android研究员(自封的),后续会尝试下DirtyPipe利用到Android系统中完成提权。相信也会非常有趣吧.期待能慢慢学到更多的知识。
Reference
bsauce 整理expolit : 【kernel exploit】CVE-2022-0847 Dirty Pipe 漏洞分析与利用 — bsauce
360 解析 : Linux 内核 DirtyPipe 任意只读文件覆写漏洞(CVE-2022-0847)分析-安全客 - 安全资讯平台
华为安全团队(最详细的解读) : GitHub - chenaotian/CVE-2022-0847: CVE-2022-0847 POC and Docker and Analysis write up
漏洞环境 : https://github.com/N1rv0us/kernel_exploitation/tree/main/CVE-2022-0847
15.1. The Page Cache - Understanding the Linux Kernel, 3rd Edition [Book]